データ分析の心構え
データ分析の心構え
最近は何かとデータ分析を業務で行うことが多く、 データ分析を行う際に自分自身が気をつけたいことなど、自分への戒めの気持ちも込めて綴りました。 まだまだ未熟な点もあるので、コメント等でご指摘・ご鞭撻のほどご教授願い致します。 今回のブログでは、あまりpandasのことについては触れません、なぜならデータを分析する前に重要なことがあるからです。 pandasの扱い方については、またの機会に紹介します。

はじめに
このエントリを見ている方は、データ分析、機械学習、あるいは、マーケティング分析など、分析に興味がある人ではないかと思います。 ところで、分析とはなんでしょうか?あなたが思う分析はなんでしょうか。少し考えてみてください。。。。
データの分析はなぜ行うのでしょうか、なぜ必要なのでしょうか。一度考えてみてください。 このブログでは私なりの答えと、私自身がもっと実践すべきことを自分への戒めを込めて紹介します。
分析とは何か
多くの語そのものに色々な意味があるように、分析にも色々な意味がありますが、 このブログでは、分析とは公平に分析対象を比較すること*1と定義します。
分析結果は通常、研究であれば論文になり、仕事であれば上司に見せたり、施策の採択の意思決定に繋がるものであり、 分析過程は気にされることは殆どありません。したがって、分析するのは自分自身であるので、 結果はいくらでも自分の好きなように操作可能であるからこそ重要なことでです。 自分の仮説通りに行くように仮説にとって都合の良いデータ分析手法をとれば、それは不公平であると言えます。
次に、なぜ比較が必要なのでしょうか。例えば、「私は身長が低い」と主張したとします。しかしながら、 これだけの主張だと私の身長が低いかどうか判断できません。なぜなら、比較していないからです。 代わりに、「私の身長は日本人平均身長と比較して約10cmも低い」と主張されればこれは分析であり、 意思決定を行う際の判断基準となります。ここでの判断は「私の身長は日本人平均よりも低い」となります。(これは悲しいことに 事実です。)さらに、分析の際には縦、横軸を明確にすることが重要です。軸が比較するのに適していなければ、 それは良い分析とは言えずそれによる意思決定も困難になってしまいます。今回の例だと、下図のように横に自分、平均的な日本人、 縦が身長(cm)となります。
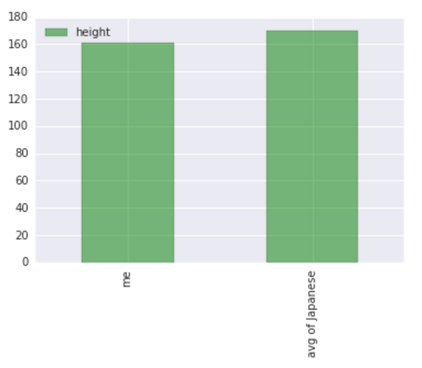
上のグラフの作成方法 import pandas as pd import seaborn as sns height = pd.DataFrame([16x, 170], index=['me', 'avg of Japanese'], columns=['height']) height.plot(kind='bar', color='g', alpha=0.5)
なぜ分析を行うのか
分析の定義は比較することだと述べましたが、なぜ分析を行うのでしょうか。 私の考えでは、分析はあるイシューに対する意思決定を行う際の判断材料です。そのため、意思決定をサポートするために分析を行うと考えています。 ここでいう、イシューとは答えを出し得る仮説のことです。 判断材料になるというのは、分析を行っても100%これだと言える結果がビジネス、研究の世界でもいつも出るとは限らないからです。 よって、分析は仮説の確からしさを向上させるものであって、それを保証するものではありません。それゆえに、試行回数とスピードを重視することが重要でもあります。 分析は仮説の確からしさを上げるものでもありますが、90%の確からしを保証するのには骨が折れます。しかし、それよりも低い70%程度であればあまり時間はかかりません。一般的に、質を高める程ある閾値から時間が2,3倍とかかってしまうと思います。 どんな分析、イシュー、仮説であれ、答えが出てやっと価値のある仕事となります。そのため、丁寧にやりすぎず試行回数とスピードを 重視すること、つまり、70%の分析を複数回行うことで確からしさを向上させ、素早く答えを出すのが最終的により価値のある分析と言えるでしょう。
どんな問題に取り組むのか
分析を行う意味について、あるイシューに対する意思決定の判断材料と答えました。 つまり、最終的に成し遂げたいのは意思決定です。 では、どんな意思決定を成し遂げれば良いのか、ここが肝となります。 イシューからはじめよの本でも言及されているように、一番大切なのは「答えを出す価値がある問題」に対して取り組んでいるか否かです。 つまり、イシュー度の高い問題に取り組むことが一番大切であり、同時に難しいことでもあります。 したがって、目先の分析、調査に没頭するのではなく、今取り組んでいるイシューが本当にイシュー度が高いものなのかと常に自問自答していきたいと思っています。 分析者などに陥りがちな点として目先の分析技術などに没頭し、イシュー度が低い問題に取り組んでしまうことです。常に自分が正しいイシューと向き合っているかを自問していきたいと考えています。
pandasを利用した分析のTips
今回のブログでは、pythonに関するadvent calendarであるにも関わらず、ほとんどpandasのことについては触れなかったので、ここで私がいつも利用している機能、ライブラリ等を紹介します。
- anaconda:分析に必要なほとんどのライブラリを揃えたパッケージマネージャー
- pandas: 提供するリッチなデータフレームを提供
- ipython notebook
- matplotlib
- seabron: seabornはmatplotlibによるグラフを簡単に綺麗に出力したり、violinplotのようなグラフも簡単に描画できる
- pandas-td: Treasure Data*2からデータを取得する際に利用
- pandas-rs: Amazon Redshift*3からデータ取得をする際に利用。
- scipy, scikit-learn: 機械学習を行うときに利用
ipythonで開発するときの便利な機能
%matplotlib inline # インラインで図を描画
%psource obj # objのソースコードがすぐに参照可能。Rubyにあるpryのshow-sourceに対応。
from IPython import embed def foo(): hoge_func() embed() # hoge_funcとbarの間でipythonのインタープリターを起動。Rubyでいうbinding.pry bar()
参考になる書籍の紹介
- イシューから考える重要性を教えてくれます。
「科学的思考」のレッスン―学校で教えてくれないサイエンス (NHK出版新書)
- 論理的に考えること、良い・悪い仮説の判断の方法など多岐に渡る本です
- クリティカルな考え方、分析哲学の入門
学会・論文発表のための統計学―統計パッケージを誤用しないために
- 統計のはまりどころ、気をつけたほうが良いことが網羅されており、実務の統計処理などでも十分に使えます
10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く (Informatics &IDEA)
- pandasを扱うにしろ、何にしろデータ分析はSQLができないと何も始まりません。これ一冊でSQLはかなり使えるようになります。ちなみに、pandasのデータフレームはsql風に扱えるようにもなっており、SQLがわからないとpandasも使いこなせないと思います。
pandas: powerful Python data analysis toolkit — pandas 0.17.1 documentation
- pandasのdocumentはものすごく充実しており、pandasを理解するのに別途本は必要ありません。
scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation
- scikit-learnもpandasと同様にdocumentが充実しており、全てdoucmentで完結できます
まだまだ、紹介したいの本はありますがここら辺でやめておきます。