データ分析の心構え
データ分析の心構え
最近は何かとデータ分析を業務で行うことが多く、 データ分析を行う際に自分自身が気をつけたいことなど、自分への戒めの気持ちも込めて綴りました。 まだまだ未熟な点もあるので、コメント等でご指摘・ご鞭撻のほどご教授願い致します。 今回のブログでは、あまりpandasのことについては触れません、なぜならデータを分析する前に重要なことがあるからです。 pandasの扱い方については、またの機会に紹介します。

はじめに
このエントリを見ている方は、データ分析、機械学習、あるいは、マーケティング分析など、分析に興味がある人ではないかと思います。 ところで、分析とはなんでしょうか?あなたが思う分析はなんでしょうか。少し考えてみてください。。。。
データの分析はなぜ行うのでしょうか、なぜ必要なのでしょうか。一度考えてみてください。 このブログでは私なりの答えと、私自身がもっと実践すべきことを自分への戒めを込めて紹介します。
分析とは何か
多くの語そのものに色々な意味があるように、分析にも色々な意味がありますが、 このブログでは、分析とは公平に分析対象を比較すること*1と定義します。
分析結果は通常、研究であれば論文になり、仕事であれば上司に見せたり、施策の採択の意思決定に繋がるものであり、 分析過程は気にされることは殆どありません。したがって、分析するのは自分自身であるので、 結果はいくらでも自分の好きなように操作可能であるからこそ重要なことでです。 自分の仮説通りに行くように仮説にとって都合の良いデータ分析手法をとれば、それは不公平であると言えます。
次に、なぜ比較が必要なのでしょうか。例えば、「私は身長が低い」と主張したとします。しかしながら、 これだけの主張だと私の身長が低いかどうか判断できません。なぜなら、比較していないからです。 代わりに、「私の身長は日本人平均身長と比較して約10cmも低い」と主張されればこれは分析であり、 意思決定を行う際の判断基準となります。ここでの判断は「私の身長は日本人平均よりも低い」となります。(これは悲しいことに 事実です。)さらに、分析の際には縦、横軸を明確にすることが重要です。軸が比較するのに適していなければ、 それは良い分析とは言えずそれによる意思決定も困難になってしまいます。今回の例だと、下図のように横に自分、平均的な日本人、 縦が身長(cm)となります。
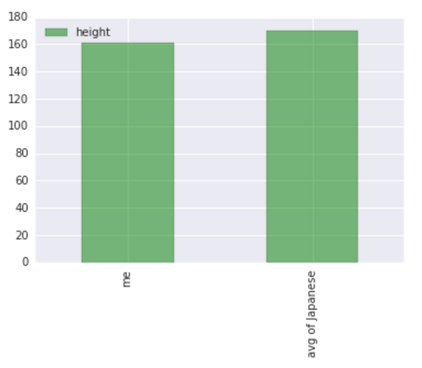
上のグラフの作成方法 import pandas as pd import seaborn as sns height = pd.DataFrame([16x, 170], index=['me', 'avg of Japanese'], columns=['height']) height.plot(kind='bar', color='g', alpha=0.5)
なぜ分析を行うのか
分析の定義は比較することだと述べましたが、なぜ分析を行うのでしょうか。 私の考えでは、分析はあるイシューに対する意思決定を行う際の判断材料です。そのため、意思決定をサポートするために分析を行うと考えています。 ここでいう、イシューとは答えを出し得る仮説のことです。 判断材料になるというのは、分析を行っても100%これだと言える結果がビジネス、研究の世界でもいつも出るとは限らないからです。 よって、分析は仮説の確からしさを向上させるものであって、それを保証するものではありません。それゆえに、試行回数とスピードを重視することが重要でもあります。 分析は仮説の確からしさを上げるものでもありますが、90%の確からしを保証するのには骨が折れます。しかし、それよりも低い70%程度であればあまり時間はかかりません。一般的に、質を高める程ある閾値から時間が2,3倍とかかってしまうと思います。 どんな分析、イシュー、仮説であれ、答えが出てやっと価値のある仕事となります。そのため、丁寧にやりすぎず試行回数とスピードを 重視すること、つまり、70%の分析を複数回行うことで確からしさを向上させ、素早く答えを出すのが最終的により価値のある分析と言えるでしょう。
どんな問題に取り組むのか
分析を行う意味について、あるイシューに対する意思決定の判断材料と答えました。 つまり、最終的に成し遂げたいのは意思決定です。 では、どんな意思決定を成し遂げれば良いのか、ここが肝となります。 イシューからはじめよの本でも言及されているように、一番大切なのは「答えを出す価値がある問題」に対して取り組んでいるか否かです。 つまり、イシュー度の高い問題に取り組むことが一番大切であり、同時に難しいことでもあります。 したがって、目先の分析、調査に没頭するのではなく、今取り組んでいるイシューが本当にイシュー度が高いものなのかと常に自問自答していきたいと思っています。 分析者などに陥りがちな点として目先の分析技術などに没頭し、イシュー度が低い問題に取り組んでしまうことです。常に自分が正しいイシューと向き合っているかを自問していきたいと考えています。
pandasを利用した分析のTips
今回のブログでは、pythonに関するadvent calendarであるにも関わらず、ほとんどpandasのことについては触れなかったので、ここで私がいつも利用している機能、ライブラリ等を紹介します。
- anaconda:分析に必要なほとんどのライブラリを揃えたパッケージマネージャー
- pandas: 提供するリッチなデータフレームを提供
- ipython notebook
- matplotlib
- seabron: seabornはmatplotlibによるグラフを簡単に綺麗に出力したり、violinplotのようなグラフも簡単に描画できる
- pandas-td: Treasure Data*2からデータを取得する際に利用
- pandas-rs: Amazon Redshift*3からデータ取得をする際に利用。
- scipy, scikit-learn: 機械学習を行うときに利用
ipythonで開発するときの便利な機能
%matplotlib inline # インラインで図を描画
%psource obj # objのソースコードがすぐに参照可能。Rubyにあるpryのshow-sourceに対応。
from IPython import embed def foo(): hoge_func() embed() # hoge_funcとbarの間でipythonのインタープリターを起動。Rubyでいうbinding.pry bar()
参考になる書籍の紹介
- イシューから考える重要性を教えてくれます。
「科学的思考」のレッスン―学校で教えてくれないサイエンス (NHK出版新書)
- 論理的に考えること、良い・悪い仮説の判断の方法など多岐に渡る本です
- クリティカルな考え方、分析哲学の入門
学会・論文発表のための統計学―統計パッケージを誤用しないために
- 統計のはまりどころ、気をつけたほうが良いことが網羅されており、実務の統計処理などでも十分に使えます
10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く (Informatics &IDEA)
- pandasを扱うにしろ、何にしろデータ分析はSQLができないと何も始まりません。これ一冊でSQLはかなり使えるようになります。ちなみに、pandasのデータフレームはsql風に扱えるようにもなっており、SQLがわからないとpandasも使いこなせないと思います。
pandas: powerful Python data analysis toolkit — pandas 0.17.1 documentation
- pandasのdocumentはものすごく充実しており、pandasを理解するのに別途本は必要ありません。
scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation
- scikit-learnもpandasと同様にdocumentが充実しており、全てdoucmentで完結できます
まだまだ、紹介したいの本はありますがここら辺でやめておきます。
pandas-rsをリリースしました
pandas-rsをリリースしました
pandasから簡単にPostgreSQLあるいはAWSのサービスであるRedsfhit^1につなげる簡単なライブラリを書きました。 適当に書いたコードなので一部臭いのです。修正のPRお待ちしています。 pandas-rsはTreasureData^2さんが開発しているpandas-tdに影響を受けて作りました。
レポジトリはここ↓ github.com
PR待ってます。
postgresが必要です
Macの場合。postgresqlが入っている必要があります。元から入っている場合は必要ありません。
brew update brew install --force ossp-uuid brew install postgresql
インストール方法
pip install pandas-rs
使い方
Shellで、passwordをエクスポートすることを推奨しています。
export REDSHIFT_PASSWORD='password'
shellでpasswordをエクスポートしたら、import osをし、環境変数からpasswordを取り出しましょう。
pandas-rsはimport pandas_rs as rsでインポートします。
rs.create_engineで、redshfitにつなげる設定を行います。
import pandas_rs as rs import os # use only if you will access password through environment variables rs.create_engine( dbname='dev', user='test', password=os.environ['REDSHIFT_PASSWORD'], host='foobar.redshift.exmple', port='5439' )
設定が終わったら。 あとはsqlを流すだけです
print(rs.read_sql("select 'hello redshift' greeting"))
上記の結果は以下のようになります
greeting
0 hello redshift
もちろんpandasなので、そのままグラフの描画も(matplotlibが必要になります)
import matplotlib.pyplot as plt # %matplotlib inline #if you use ipython notebook rs.read_sql(""" select * from some_data """).hist()
そうすると簡単に描画できます。
(Pythonによる簡単なLispインタープリタ実装方法(四則演算編))
この記事はPython Advent Calendar 2014 11日目の記事です
Pythonによる簡単なLispインタープリタ実装方法
lispのインタープリタの実装を行う事により,プログラミング,コンピュータへの知識を 深める事を目的としています.今回は,以下のように2部に分けてLispインタープリタ実装方法を紹介します. (ただ,lispで四則演算ができるインタープリタを作成できれば,インタープリタの概念は理解出来ると思います.また,今回はpython3以降を想定しています.)
- 四則演算編
- 関数編 (
一週間後くらいに書きます.すみません.すこし落ち着いたら書きます.)
なお,今回のLispインタープリタ実装を紹介するきっかけとなったのが,「ギークエンジニア必見!Lispインタープリター」勉強会 with すごい広島 - すごい広島 | Doorkeeperに参加した事でした.これを機にPythonでも実装してみようと思いました.幸い,Peterさんがブログ(How to Write a (Lisp) Interpreter (in Python))で既にPythonでの実装を紹介しております.今回はこのブログを参考にし,lispインタープリタ実装を紹介したいと思います.
先に,彼らに敬意と感謝の気持ちを記しておきたいと思います. さて,前置きが長くなりましたが,まずは四則演算編を紹介していきたいと思います.
インタープリタ概要
さて,今回はインタープリタを作りたいわけですが,インタープリタってどう動作するのでしょうか. 簡単に図示すると以下の通りになります.
プログラム(文字列)⇒ 構文解析器 ⇒ 構文木(list) ⇒ 評価(eval) ⇒ 結果
となります.つまり,文字列であるプログラムを構文解析器に入れます.そうすると,構文木(今回はpythonで扱える構造なのでlist)が 出来上がります.構文木はインタープリタ内で処理出来る形です.最後に構文木を評価しプログラムが意図している結果を出力します.
実際に作成したインタープリタでは,以下のようなステップを踏んでプログラムを評価(実行)します.
>>> program = "(* 1 3)" # このようなプログラムがあります # プログラムをparser(構文解析器)に入れます. >>> ast = parse(program) # 構文木を生成します.astはabstract syntax tree(抽象構文木の略) >>> ast ['*', 1, 3] #このようにPythonで扱えるようなlist構造に変換します(つまり,インタープリタで扱える構文木になっている) >>> eval(ast) # astを評価 4 # 1 * 3の結果
行っている事は凄い単純です.文字列をインタープリタ(python)が扱える形に変換して,それをlispの構文に沿って解釈するだけです. 以上が,概要となります.次は,四則演算を早速作っていきましょう.
四則演算作成に当たって,以下の事を順に説明していきます.
- 文字列からトークンを生成する(字句解析(Lexical Analysis))⇒
tokenize - 1の結果を用いて構文解析をする(Syntactic Analysis)⇒
parse - 四則演算等の手続きを参照可能とする環境(Enviornment)の構築(メモリの構築) ⇒
starndard_env - 2の結果を評価(eval)する
1. 字句解析(Lexical Analysis)
構文解析は字句解析と構文解析部に分けられます.字句解析では,意味のあるトークンに分けます.
本来ならば,正規表現を使うべきですが,インタープリタの動作を理解するのが本稿の目的なのでそこは割愛します.
今回の字句解析は以下のようにカッコにスペースを追加する形にして(replace),スペースでトークンを区切ります(split).
def tokenize(chars): return chars.replace('(', ' ( ').replace(')', ' ) ').split()
実行例
>>> tokenize("(* 1 3)") ['(', '*', '1', '3', ')'] #トークン毎に分離 >>> tokenize("(define square (lambda (r) (* r r)))") #square関数の定義(これは関数編で詳しく見ていきます.) ['(', 'define', 'square', '(', 'lambda', '(', 'r', ')', '(', '*', 'r', 'r', ')', ')', ')']
2. 構文解析(Syntactic Analysis)
さて,次に構文解析ですが,構文解析は3つの関数から構築していきます.
parseはプログラムを字句解析した結果を読み込む関数read_from_tokensのラッパー関数です.
def parse(program): return read_from_tokens(tokenize(program))
次に,read_from_tokensを見ていきましょう.
3行目:関数tokenizeの結果tokensはlistなので,pop(0)で最初の要素をtokenに入れます.
11行目:tokenが)から始まるとエラーSyntaxError('unexpected')を返します.
12行目:tokenが(,)のどちらでも無ければ,文字列であるシンボルを正しい型に変換する関数atomに渡す.
14行目から始まるatomは単純にintキャストを試みて,ダメだったらfloat,ダメだったらstrを返す関数です.
ここまでで,read_from_tokensがシンボルがあれば,シンボルを適切な値にして返す関数である事がわかりました.
次に,
4行目:tokenが(から始まるのであれば以下の動作を行います.
新しいリストLを作成しtokensの最初の要素が)になるまで再帰的に自分の返り値をLに入れる.
つまり,1つのカッコの始まりから,終端までのトークンを入れていきます.また,その中にカッコが含まれると新しいLを作成し,
同様の動作を行います.文章で説明するのは難しいですね.例を見ていきましょう.
この関数の動作例.
プログラム(* 1 3) があるとします. parseに渡します. >>> parse("(* 1 3)") 字句解析してトークンに分けます. tokenize("(* 1 3)") ['(', '*', '1', '3', ')'] を得ます. これをread_from_tokensに渡します. read_from_tokens(tokens) すると,カッコがあるので, Lを作成(以下再帰的に実行) Lに*を入れます.atomでstr型にする. Lに1を入れます.atomでint型にする. Lに3を入れます.atomでint型にする. )まできたので,カッコを捨てます. Lを返します. read_from_tokens(tokens)の結果, ['*', 1, 3]をread_from_tokensの結果として返します(parseの結果)
で,Lなんの為にあるのと思うかもしれません.これは,カッコがネストになっている時に,
各カッコの中身を一時的に保持する役目を持ちます.一時的に保持してそれを,最終的には1つのリストに渡します.
つまり,ネスト構造をとるリストになります.[[],[],[]]のような感じ
もう1つ例を見てみましょう.
プログラム(* (* 1 3) 5) があるとします. parseに渡します. >>> parse("(* (* 1 3) 5)") 字句解析してトークンに分けます. tokenize("(* (* 1 3) 5)") ['(', '*', '(', '*', '1', '3', ')', '5', ')'] を得ます. これをread_from_tokensに渡します. read_from_tokens(tokens) すると,カッコがあるので, Lを作成(以下再帰的に実行) Lに*を入れます.atomでstr型にする. カッコがあるので, Lを作成します.(二個目のLで,これは一番最初のLとはメモリの場所が異なる.つまり,ネストしている中でのLである) Lに*を入れます.atomでstr型にする. Lに1を入れます.atomでint型にする. Lに3を入れます.atomでint型にする. )まできたので,カッコを捨てます. 結果を返します.この結果は外枠のLに渡します. Lに5を入れます.atomでint型にする. )まできたので,カッコを捨てます. Lを返します. read_from_tokens(tokens)の結果, ['*', ['*', 1, 3], 5]をread_from_tokensの結果として返します.(parseの結果)
今回は,8行目にあるように動きを確認するためにLのprint文を挟んでいます. print文の実行結果を見てましょう.
parse("(* (* 1 3) 5)")
['*']
['*']
['*', 1]
['*', 1, 3]
['*', ['*', 1, 3]]
['*', ['*', 1, 3], 5]
まさに上記で説明したように,Lに値を入れていって,カッコがきたら新しいL(list)を作ってそれを元のLに入れていくというのを, 再帰で表現する事で,lispのネストを表現しています.
かなり重複するところもありましたが,これでparseの動きが分かったかと思います.
最後にまとめると,parseは文字列であるプログラムを字句解析でトークン化し,それをインタープリタが解釈出来る形に
していきました.今回では,pythonが理解出来るlist型を利用して,構文木を表現しました.
なんかもの凄く長く書き過ぎているし,
もうやめたいと思ったりもしますけれども次に進みたいと思います.
3. 環境(Environment)
次は,環境についてです.ここまでは,文字列であるプログラムをインタープリタ内部でどう解釈していくかを
見てきました.では,*等の演算子や手続き(procedure)をどう解釈し,それを被演算子(operand)に適用していけば
良いのでしょうか.環境は,演算子・手続きとその動作を紐づけています.
では,その環境をどう表現するか見ていきましょう.pythonの辞書で紐づけていきます.
7 ~ 10行目で各演算子の記号をpythonの演算子に紐づけています.このpythonの各演算子は引数を2つとります.
e.g
>>> import operator as op >>> op.add(1,3) 4
このように,環境に各シンボルに対応づける処理のペアを格納します.
4. 評価(eval)
環境に各シンボルの行う処理のペアを格納しました.それでは,シンボルをどう評価し結果を出すのでしょうか. まず先に,復習をかねて評価までのステップ例を見ましょう.
>>> ast = parse("(* (* 1 3) 5)") #文字列のプログラムから構文木astを作成 >>> print(ast) ['*', ['*', 1, 3], 5] >>> eval(ast) #astを評価し,実行結果を得る. 15
評価では,プログラムを解析して得られた構文木を実行して結果を得ます. そのために,引数としてastと利用する環境を指定します.
では,実行例を交えてコードの解説に入ります.
>>> ast = parse("(* (* 1 3) 5)") #['*', ['*', 1, 3], 5] >>> eval(ast)
上記のとき,まずevalでは,listであるastを引数と取り,環境envは先程定義した環境(global env)を利用します.
1. x(=ast)はシンボルでなく,リストであるので,一番最後のブロック(7行目~)が実行されます. 2. 手続きprocとして,astの最初の要素を再帰的に評価します.評価結果がprcに代入されます. 2.1 x(='*')はシンボルなので,3行目が実行されます.3行目では,環境に入っている関数を呼び出します.この場合`op.mul`を返し,procにop.mulを代入します 3 引数argsとして,最初の要素以外の部分を全て評価し,引数としてargsに代入します. 3.1 まず最初はargsに['*', 1, 3]が割り当てられ,これが評価されていきます 3.1.1 2.1, 2.2と同様に'*'が評価され,procにop.mulが代入されます. 3.1.2 x(=1)はシンボルでも,リストでも無いので,そのまま1を返します 3.1.3 x(=3)はシンボルでも,リストでも無いので,そのまま3を返します 3.1.4 args = [1,3]をとり,op.mul(1,3)が実行され,3を返します. 2.2 x(=5)はシンボルでも,リストでも無いので,そのまま5を返します 2.3 args = [3,5]をとり,op.mul(3,5)が実行され,15を返します. 結果,15が得られます
このように再帰的に,に演算子・手続きを被演算子に適用し評価していく形をとり,最終的な評価を行います. これで,演算子を評価するlispインタープリタが作成する事ができました.
REPL(read-evaluation-print-loop)を実装すればインタープリタのように実行し,結果の確認をする事ができます. 簡単に記述すると以下のようになります.
どうでしょうか,演算子を評価出来る簡単なlispインタープリタを作成できました. 単純な動作を積み上げていくだけでインタープリタが作成できるのは凄く面白かったと思います.
次回は,関数定義,if文等を実装してlispプログラミングできるようにしていきたいと思います. ですが,今回の演算子の作成方法が分かればあとは自分で作る事も可能です.次回の投稿までに 実装方法を考えてみて下さい.
今回の全体を通してのコードは以下のようになります.